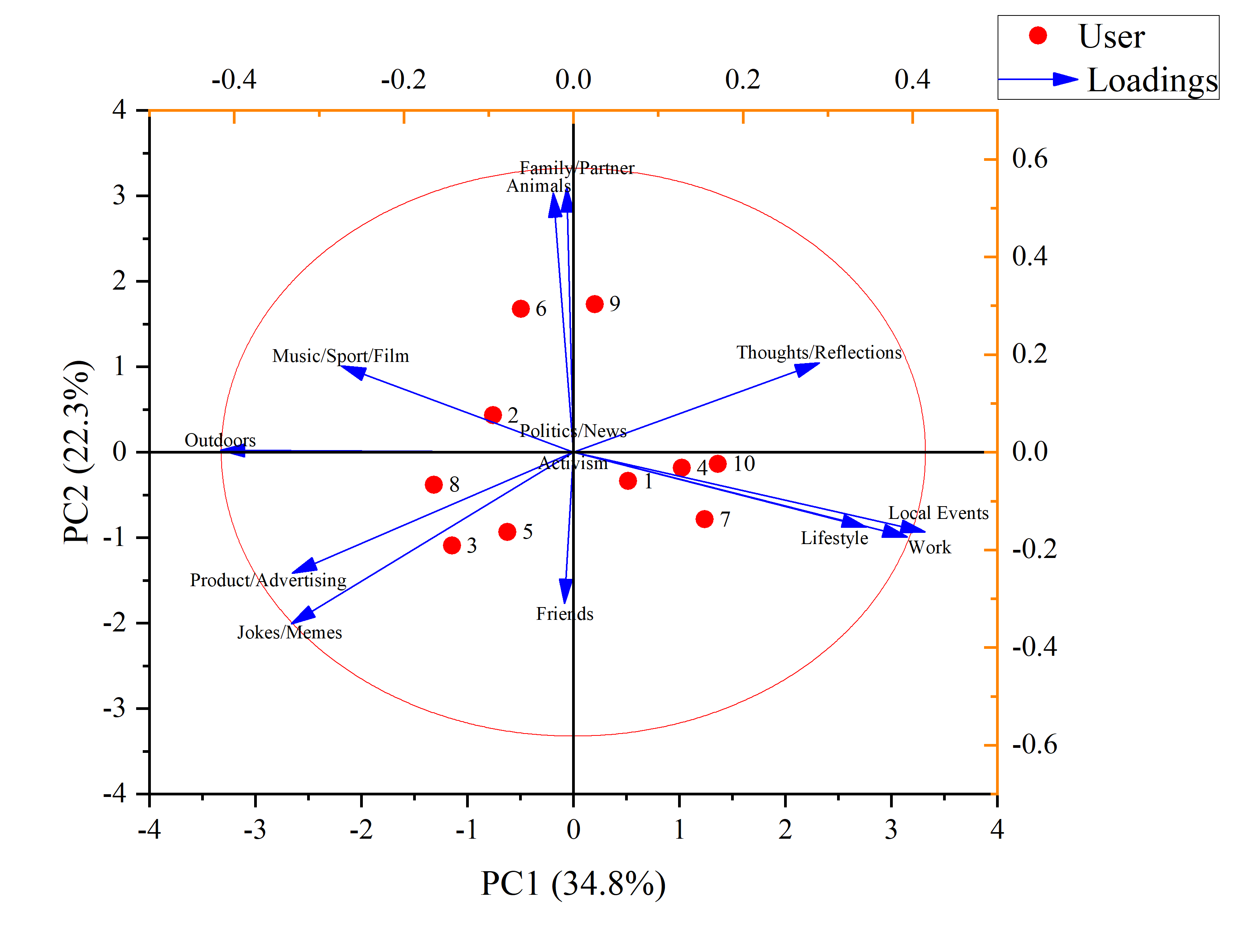
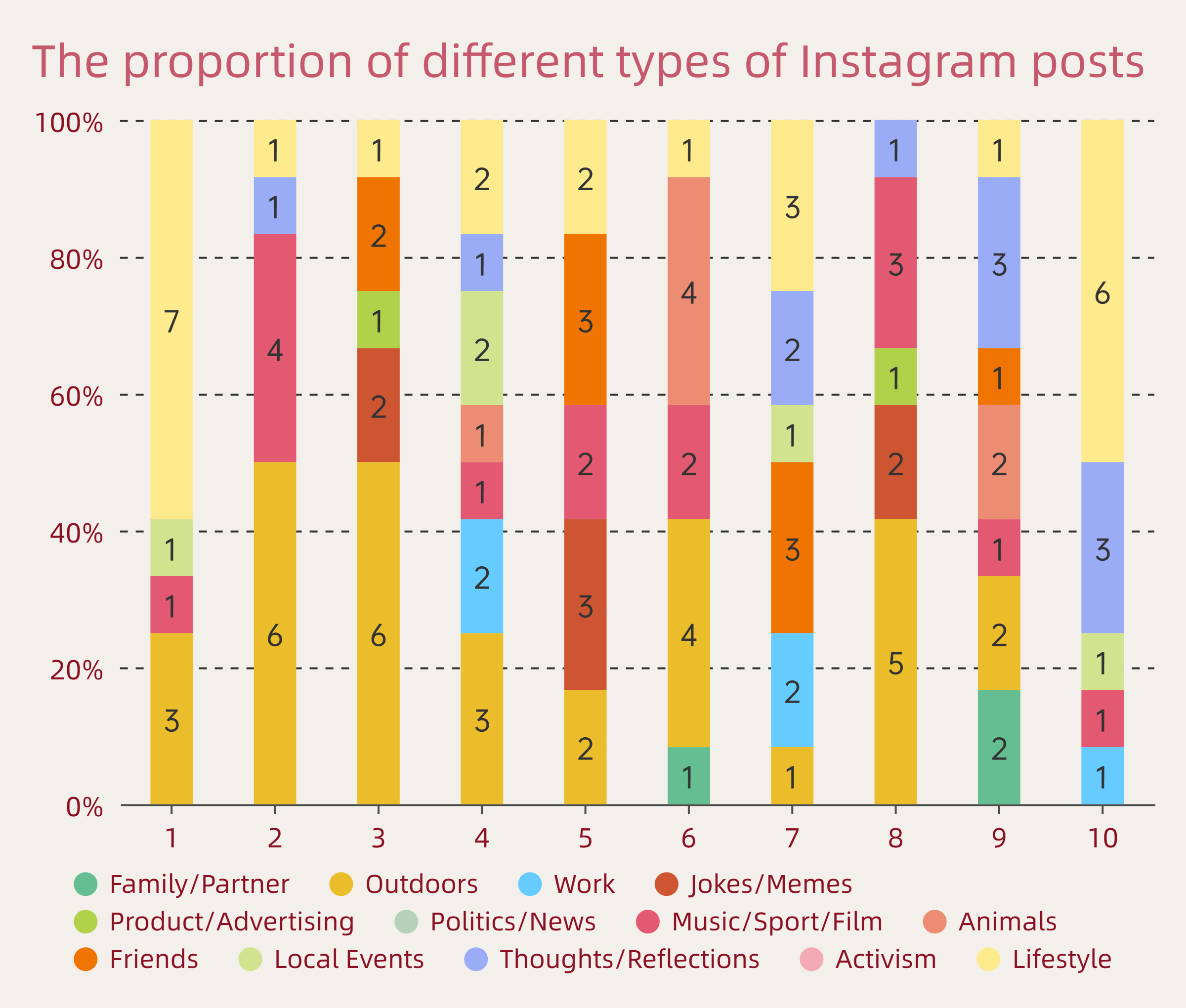
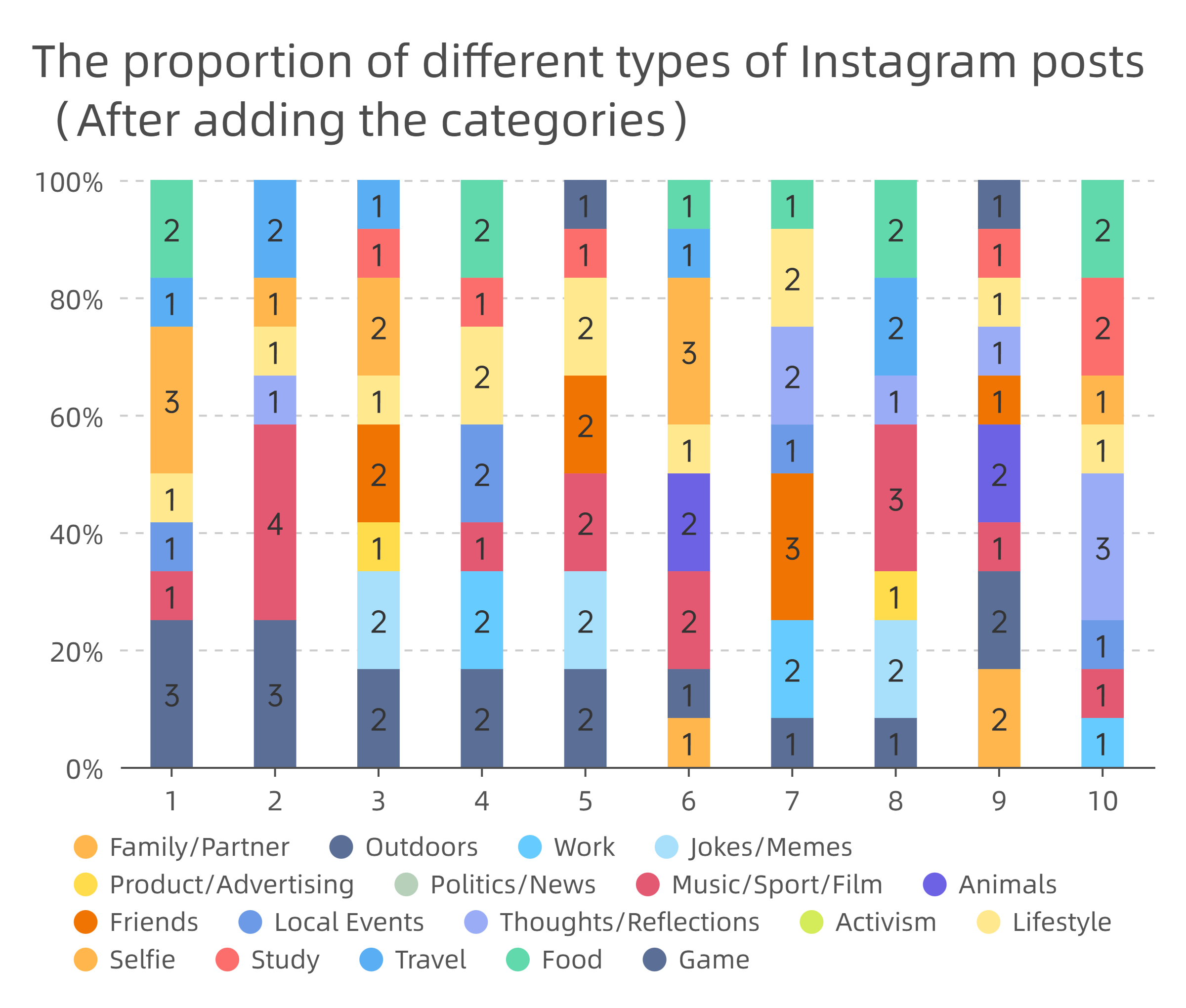
Week 1 — Introduction to Digital Practices
This week’s lecture focused on conducting critical thinking about digital media from both social and material perspectives, particularly introducing the Technological determinism, Social shaping, and Social Construction of Technology (SCOT).
💭 Is AI making us dumb?
AI can become a tool for developing our intelligence.
There is an interesting question - "Is AI making us dumb?". It makes me to reflect not only on technology, but also on how we define artificial intelligence. On the one hand, artificial intelligence can learn quickly and complete tasks efficiently, such as translation, writing, code modification, and so on. These tasks, before the advent of artificial intelligence, often required people to undergo long-term learning to master the skills. The convenience brought by artificial intelligence may lead to a decrease in our enthusiasm for responding to problems ourselves. If we throw all the problems we encounter to AI and let them help us think, then we ourselves may no longer engage in independent thinking (even if we already possess those skills).
On the other hand, perhaps the statement that "Artificial intelligence makes us stupider" is overly simplistic. Artificial intelligence helps improve human thinking efficiency. It enables us to handle large amounts of data and quickly identify the key points. People can also create at a higher level based on the output of artificial intelligence - this is how artificial intelligence allows us to use our intelligence in new ways. Previously, we thought that being smart meant being able to remember things, calculate quickly, write well, and so on. But now that artificial intelligence can do all these things, human "intelligence" can be manifested in more aspects, such as critical thinking, and emotional understanding.
Therefore, from this perspective, whether artificial intelligence makes us stupid depends on our relationship with it. If we use artificial intelligence passively, then it may weaken our enthusiasm for learning knowledge. But if we use it critically, questioning its output and integrating it into our own thinking - then artificial intelligence can become a tool for developing our intelligence. Therefore, the question may not lie with artificial intelligence itself, but with its designers and users - how we cultivate digital literacy and self-awareness
Don't blindly accept technology.
Many of us habitually believe that technology is neutral, such as mobile phones, the internet, and AI. We think they are merely tools, and their goodness or badness depends on how people use them. But this statement is reminding us that technology itself also has a "character" and a "stance". It is not just a passive machine; it is shaped by social, political, cultural, and economic factors. It is not neutral. Technological determinism holds that technology itself drives social change, and humans merely follow along. For example, the steam engine drove the Industrial Revolution, and shipbuilding technology drove maritime trade. However, it also ignores some important issues: Who designed this technology? Who does it serve? Who is neglected?
The Social shaping theory holds that society and technology mutually determine each other. For instance, the previous capitalist economic structure, labor shortage, and the development of new energy sources, among other social conditions, facilitated the research and popularization of the steam engine, thereby driving the Industrial Revolution. This emphasizes that technology has economic value and emotional bias.
SCOT goes further to say that the "meaning" of technology itself is also socially constructed. The same technology has completely different uses in different positions, and different groups give it different values. For example, some social media is a space for sharing life and building social relationships for young people, an important marketing channel for advertisers, and a tool for public opinion dissemination and control for the government.
Technology is like a mirror, and each group will see what they want to see in it. What we can do is not to blindly accept technology, but to consciously use and examine it.